


.png?width=610&name=J1_ModernCybersecurityBook_Promo%201200x628%20v2@2x%20(1).png)

Marc Cluet is a leader in the DevOps community in London, and he’s the tech lead at the Nationwide Building Society. In the session “Your Kernel and You—How cgroups Make Containers Possible,” he dives into how containers work by exploring cgroups. A lot of people know about Docker and what it does, but very few know what makes Docker and other wonderful tools possible.
In this talk, Cluet discussed oversight on how CNAMES, or canonical names, work, how namespaces work in the kernel, and more.
A Quick History of Containers
Containers are not actually new. They have a rich history with Unix that started in 1979. They evolved heavily in the early 2000s when Oracle got involved. Google created cgroups around 2006 to enable their Borg infrastructure, an app clustering system that is a spiritual precursor to Kubernetes.
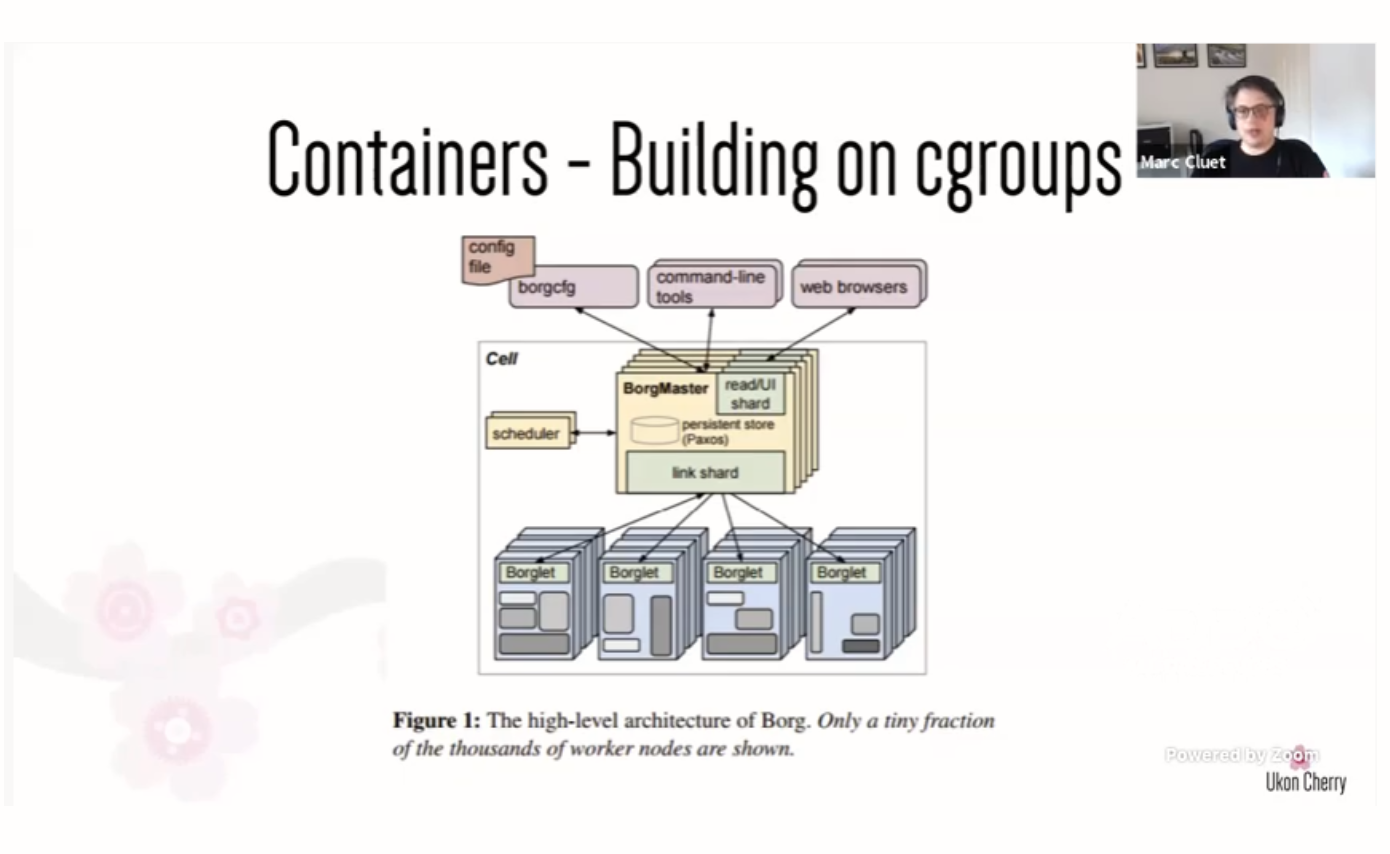
At first, we only had lxc for command line support for cgroups. Then Docker came along to make it easier to work with cgroups.
What We Need for Containers
In order to have containers, we need a few things:
- Isolated filesystem: This ensures one service does not override or delete another service’s data.
- Isolated memory: This helps us avoid leaks or one service accidentally starving another service.
- Isolated CPU: Similar to memory, this ensures every service has enough CPU to perform the calculations they need.
- Isolated users: This ensures every service can be secure and that data won’t leak out inappropriately.
- Isolated network: This ensures each service can have stable traffic to and from the outside world.
- Resource limiting: This ensures every service has what it needs to get its job done.
- Accounting and calculating consumption: This lets the infrastructure make changes to containers as necessary to scale a service appropriately.
To achieve this, we have different namespaces in a Unix kernel:
- Mount: This lets us isolate filesystems.
- UTS: This is a special namespace because in Unix. Everything is a file and is heavily tied to the hostname. UTS lets us isolate network calls and put multiple hostnames on one server.
- IPC: This lets us isolate a subset of network calls with multiple hostnames.
- PID: This lets us isolate memory by having isolated process IDs (PIDs)
- User: This namespace lets us isolate users and groups inside the container.
- Cgroup: This is the main tool for isolation and gives us accounting and control. We can use cgroups to measure consumption and limit resources.
- Time: This lets us manage time in an isolated manner.
- Syslog: This lets us have multiple “server logs” in one server.
Not only do we have a plethora of namespaces to leverage, but they are composable. We can have a hierarchy of namespace.
Cgroups: a Brief History
As seen above, cgroups is a namespace, but it’s not very popular to use the term “cgroup” these days. The use of their name has evolved, as have their features. Cgroups originally needed to be isolated per thread, and you could only have 12 of them.

At the time of writing, cgroups have been around for 14 years. They needed to evolve to give us the rich functionality we see in containers today.
Cgroups version 2.0 was a complete rewrite of them. They add isolation per process, not thread, and make better use of namespaces. They could also live next to the v1 of cgroups. For example, in Bash, you can use the “cgroup2” tool instead of “cgroup.”
Leveraging the Power of Cgroups
To conclude, cgroups enable an incredible array of tooling for isolating software. They are built on top of namespaces and are composable. Hopefully, this reveals some of the magic behind containers.
This post was written by Mark Henke. Mark has spent over 10 years architecting systems that talk to other systems, doing DevOps before it was cool, and matching software to its business function. Every developer is a leader of something on their team, and he wants to help them see that.
Photo by frank mckenna

