


.png?width=610&name=J1_ModernCybersecurityBook_Promo%201200x628%20v2@2x%20(1).png)

Software is becoming ubiquitous and its correctness matters a lot, especially when it operates critical functions. Writing software that works is only one aspect of the job, the most complicated task is to maintain it so that it can be built and maintained properly for years to come.
For that reason, it is becoming increasingly important not only to write correct software but also make sure it is maintainable. Over the years, various software metrics emerged (such as code coverage, number of violations, connectedness between modules, etc) to help developers and managers understand the cause of maintenance issues.
In a paper in the well-respected International Conference of Software Engineering (ICSE) published in 2008, researchers at Microsoft found out that organizational issues, code complexity, code churn and code coverage were the top predictors of software bugs. This study was also replicated in 2015 (also published in ICSE).
The main takeaway from this study is that organizational complexity matters a lot and you should address it. The other reality is that code complexity is a good measure to predict bugs. While there is a growing interest in testing and increasing code coverage, other metrics are not getting as much attention, even if they have an equal importance on the product quality.
What Complexity Measures
This is normal: complexity measures the number of paths that your code can take (as defined by the cyclomatic complexity from McCabe). As humans, our brains are limited and cannot understand all the implications and consequences of hundreds of different paths within a given function. This becomes even more difficult when the developer is not the author of the code and is trying to understand the logical paths within a function. With multiple nested paths, it is impossible to develop a mental model of all the program states. This is why units of code should be small and have low complexity (a measure between 15 and 25 is considered acceptable - tslint, a linter for Typescript, uses the value 20 by default). A good illustration of this guideline can be found in the popular linux kernel coding style that stipulates: “Functions should be short and sweet, and do just one thing.”
Risks Associated with Code Complexity
The risk of not addressing code complexity is code that is harder to understand and maintain. Developers, especially new ones, will not fully understand the code and make mistakes when fixing bugs, ultimately impacting customers. It will also slow down product development (from bug fixes to features development) and put your market share at risk as competitors might be faster than you. As devops engineers, we should include complexity metrics and integrate them in the continuous integration pipeline to ensure that no complex code is shipped.
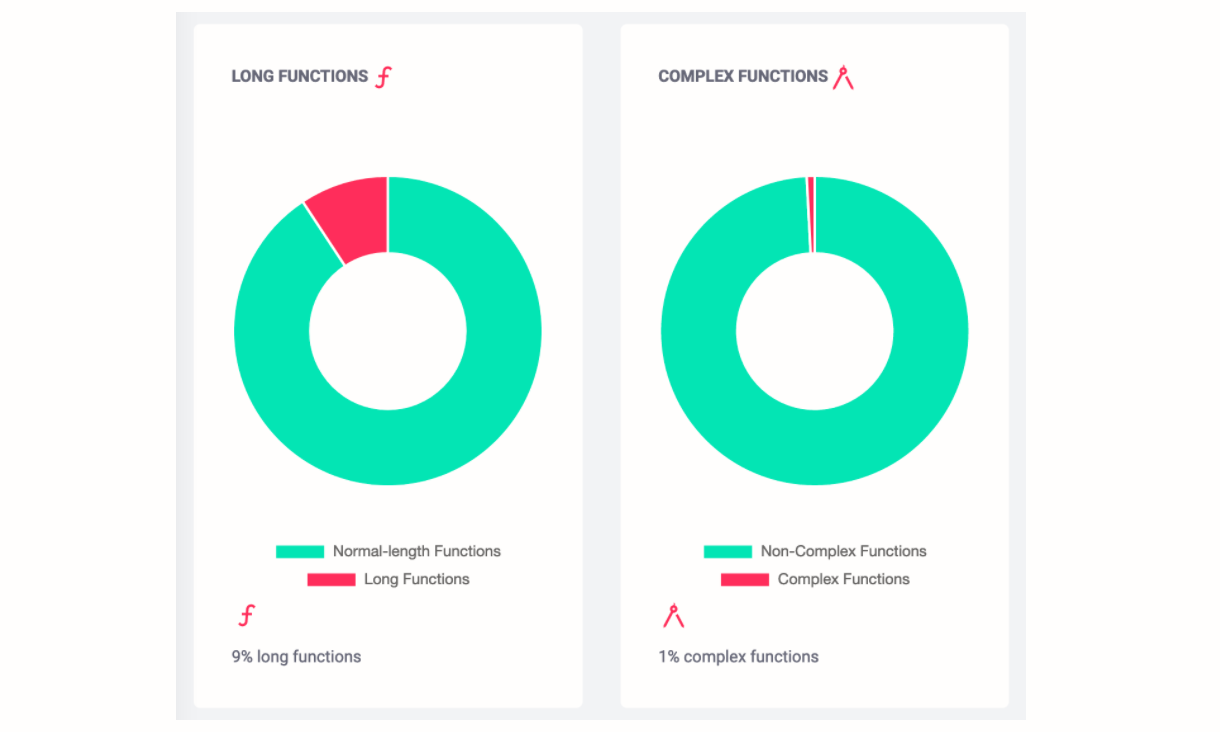
Code Analysis Platforms can help you by automatically detecting complex functions along with other software metrics
The availability of platforms such as GitHub, Bitbucket or Gitlab facilitates the integration of software analysis tools. Code complexity can be automatically extracted by static code analysis platforms (such as Code Inspector - you can try the demo of the platform). These platforms and tools can be integrated in your continuous integration pipeline to detect complex functions when reviewing code and help you avoid adding complex code in your code base.
Devops engineers can define rules that accept or reject new code based on complexity metrics, similar to how testing is done today. It is also possible to automatically detect annotate complex code when developers create pull requests (a feature also supported in Code Inspector).
Similar to code coverage, code complexity matters. By combining these different metrics, devops engineers can help teams maintain and increase software quality.

