


.png?width=610&name=J1_ModernCybersecurityBook_Promo%201200x628%20v2@2x%20(1).png)

Lambda is the eleventh letter of the Greek alphabet, and it is also the name of the Amazon Web Services (AWS) service that lets you run code without actually configuring a server. Amazon chose the name Lambda because - well, okay, I have no idea. Comment here if you know.
Thankfully, you don’t need to know that to understand how to utilize Lambda. Matt Williams, DevOps Evangelist at Datadog (@technovangelist) outlined how to setup AWS Lambda at the 2016 All Day DevOps conference in his talk titled Hold the Infrastructure: Getting the Most Out of Lambda.
First, to understand what Lambda is, we must look at the evolution of servers.
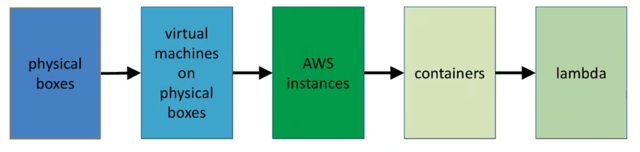
We started with physical boxes - we had to buy and maintain these boxes, and no matter how much we used, we had to pay for all of it. We then evolved to multiple virtual machines on a physical server so that we could maximize the resources of physical boxes. Now, AWS, and similar cloud services, are common. We create a virtual machine that we need, and the service provider maintains the physical servers. We also have containers to keep environments identical across machines, and, finally, we arrive at Lambda, which is service that runs code, but doesn’t require you to setup the server. It takes care of all of that automatically, and you only pay for the time that the function is actually running. So, if your function takes 500ms to run, you pay for 500ms to run it once.
Lambda is trigger based - when it receives a trigger, it executes a specified function. The trigger can be a variety of actions with AWS services, such as when a file shows up on S3 or an Alexa skill is requested.
Lambda is serverless, as far as you are concerned.
Lambda is stateless. This means you can’t rely on local states, so, if you need to retain information between function calls, you have to save that data somewhere else.
Lambda executes functions. Each Lambda function is:
- Code in a container on LXC on AMZN Linux
- Does not have restrictions on what it can do
- Priced based on exec time, quantity, and memory
Lambda links to various AWS services, such as:
- Files (S3)
- Database Updates (DynamoDB)
- Streams (Kinesis)
- Messages (SNS, SES)
- IoT (Echo, API Gateway)
Matt mentioned several good use cases for Lambda, such as bootstrapping (the first 1M requests per month are free), cron jobs, file manipulation, API translation, social media stream processing, scaling infrastructure, mobile/IoT backends, and Alexa skills, to name a few.
He also mentioned three specific examples to explore:
Matt then outlined how you can get started and noted that setup is simple as long as you think of application development as simple (write the code; setup on AWS; and debug). He walked through a specific example of automatically resizing images on S3 when they are added. You can watch his full presentation with screenshots here.
Matt also provided a list of some AWS Lambda Tools:
Matt rounded out his 30 minute presentation with a discussion regarding the need for monitoring and how to use Lambda for monitoring.
You can watch Matt’s entire talk online here, where you can dig deeper into this subject. If you missed any of the other 30-minute long presentations from All Day DevOps, they are easy to find and available free-of-charge here. Finally, be sure to register you and the rest of your team for the 2017 All Day DevOps conference here. This year’s event will offer 96 practitioner-led sessions (no vendor pitches allowed). It’s all free and online on October 24th.

