


.png?width=610&name=J1_ModernCybersecurityBook_Promo%201200x628%20v2@2x%20(1).png)

OSS (Open Source Software) is at the core of today’s information technology. About 80% of companies run their operations on OSS and 96% of applications utilize OSS as the software components. With today’s increasingly important and complex OSS, lacking software security knowledge to handle security vulnerabilities in development will result in breaches that are more serious in the future.
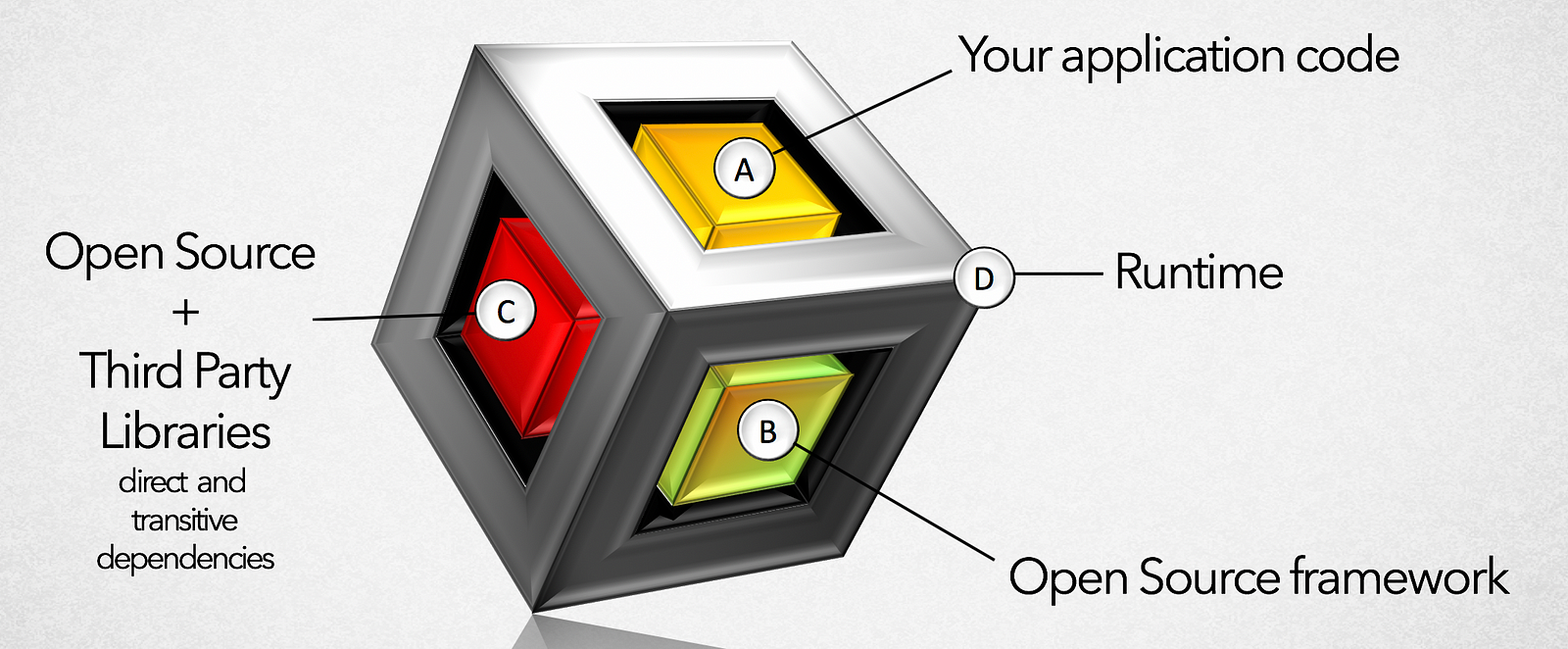
The adoption of open-source software (OSS) in the software industry has continued to grow over the past few years and many of today’s commercial products are shipped with a number of OSS libraries. Updating to a more recent, non-vulnerable version of a library represents a straightforward solution at development time.
However, the problem can be considerably more difficult to handle when a vulnerable OSS library is part of a system that has already been deployed and made available to its users. In the case of large enterprise systems that serve business-critical functions, any change (including updates) may cause system downtime and comes with the risk that new unforeseen issues arise.
The CWE standardization effort provides a unified and measurable set of software weaknesses for use in software assurance activities. CWE is a community-driven and continuously evolving taxonomy of software weaknesses. The CWE vision is two fold, enabling:
- A more effective discussion, description, selection, and use of software security tools and services that can find weaknesses in source code and operational systems
- A better understanding and management of software weaknesses related to architecture and design.
However, the CWE is often compared to a kitchen sink, as it aggregates weakness categories from many different vulnerability taxonomies, software technologies and products, and categorization perspectives. While the CWE is comprehensive, using its highly tangled web of weakness categories is a daunting task for stakeholders in the software development life cycle (SDLC).
The unique characteristics of a weakness — its workflow design or programmer errors, resources/locations that the weakness occurs in, and the consequences that follow the weakness (such as unauthorized information disclosure, modification, or destruction) — are either expressed together within a single CWE category or spread across multiple categories. Such complexity makes it difficult to trace the information expressed in the CWE.
{
"id": "b85a00e3-7d9b-49cf-9b19-b73f8ee60275",
"title": "[CVE-2017-17485] Improper Control of Generation of Code (\"Code Injection\")",
"description": "FasterXML jackson-databind through 2.8.10 and 2.9.x through 2.9.3 allows unauthenticated remote code execution because of an incomplete fix for the CVE-2017-7525 deserialization flaw. This is exploitable by sending maliciously crafted JSON input to the readValue method of the ObjectMapper, bypassing a blacklist that is ineffective if the Spring libraries are available in the classpath.",
"cvssScore": 9.8,
"cvssVector": "CVSS:3.0/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H",
"cve": "CVE-2017-17485",
"reference": "https://ossindex.sonatype.org/vuln/b85a00e3-7d9b-49cf-9b19-b73f8ee60275"
},
{
"id": "4f7e98ad-2212-45d3-ac21-089b3b082e6c",
"title": "[CVE-2018-7489] Incomplete Blacklist, Deserialization of Untrusted Data",
"description": "FasterXML jackson-databind before 2.7.9.3, 2.8.x before 2.8.11.1 and 2.9.x before 2.9.5 allows unauthenticated remote code execution because of an incomplete fix for the CVE-2017-7525 deserialization flaw. This is exploitable by sending maliciously crafted JSON input to the readValue method of the ObjectMapper, bypassing a blacklist that is ineffective if the c3p0 libraries are available in the classpath.",
"cvssScore": 9.8,
"cvssVector": "CVSS:3.0/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H",
"cve": "CVE-2018-7489",
"reference": "https://ossindex.sonatype.org/vuln/4f7e98ad-2212-45d3-ac21-089b3b082e6c"
}
The characteristics are typically documented with short, high-level textual descriptions expressed in natural language; at the same time, the assessment demands considerable expert knowledge about the application-specific use of the library in question.
Consequences of wrong assessments can be expensive: if the developer wrongly assesses that a given vulnerability is not exploitable, application users remain exposed to attackers. If she wrongly judges that it is exploitable, the effort of developing, testing, shipping, and deploying the patch to the customers’ systems is spent in vain.
While the CWE is a collection of abstract categories, the Common Vulnerability Enumeration (CVE) is an ever-growing compilation of actual known information security vulnerabilities and exposures, as reported by software development organizations, coordination centers, developers, and individuals at large. CVE assigns a common standard identifier for each discovered vulnerability to enable data exchange between security products and provide a baseline for evaluating coverage of tools and services.
We are in dire need of a semantic baseline template that effectively describes workflow design, resource locations and consequences (impact) in the event of an exploit.
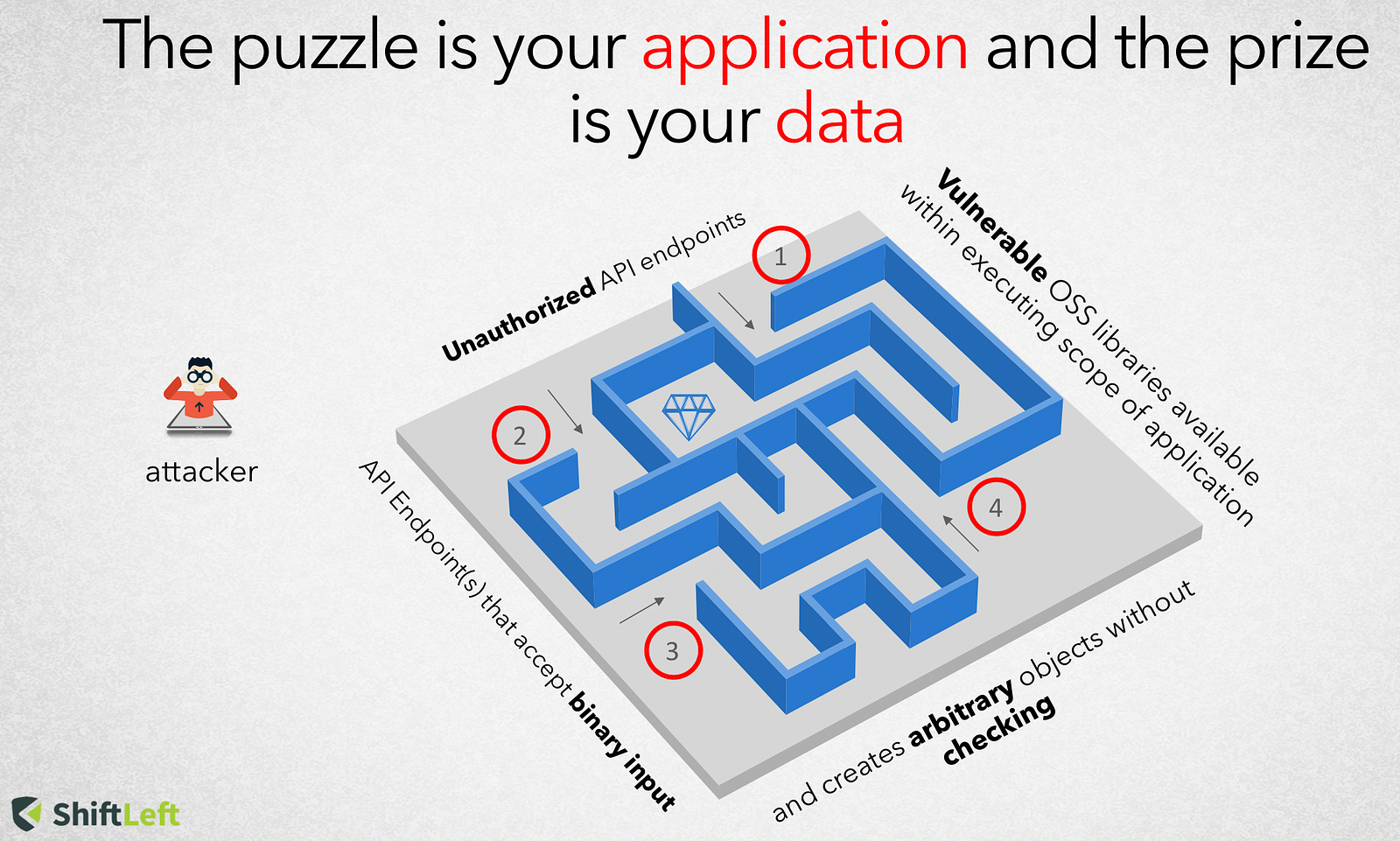
An attack typically comprises of two phases
- Injecting malicious data into the application (parameter tampering, url tampering, hidden field manipulation, http header manipulation, cookie poisoning) and
- Using the injected data to manipulating the application (SQL Injection, Cross-site Scripting, HTTP Response Splitting, Path Traversal, Command Injection)
This semantic baseline template can derive its taxonomy from the formal definition of taint propagation.
A tainted propagation problem consists of a set of source descriptors, sink descriptors, and derivation/transformation descriptors
- Source descriptors specify ways in which user-provided data can enter the program (via API endpoints, web routes, etc). They consist of a source method , one or more parameters in a variable argument list and access path applied to argument(s)
- Derivation descriptors specify how data propagates between objects in the program.
- Sink descriptors specify unsafe ways in which data may be used in the program. They consist of a sink method (file system API, HTTP response, memory access, etc) , one or more parameters in a variable argument list and access path applied to argument(s)
Given that National Vulnerability Database (NVD) provides an consistent updated feed of vulnerabilities, several vendors have emerged in this category by providing value-add service of data enrichment, taxonomy, severity scoring and indexing of vulnerability information. However most of these vendors still inherit the textual description of vulnerability characteristics rather than a semantic baseline template.
However one vendor that stands apart from the rest is Sonatype, the leader in automated open source governance. They recently released a modernized OSS Index to developers with free and easily accessible information on known open source vulnerabilities. The Index provides multi-language support, easy implementation through a REST API and native integrations with Maven Enforcer Plugin and OWASP Dependency Check. I am hoping that Sonatype will put effort in extracting intelligence from textual descriptions into a semantic baseline template (Source, Derivation and Sink descriptors).
Having this semantic template annexed to every enriched NVD record will take us one step closer to automation driven assessment of conditions leading to OSS vulnerabilities.
ShiftLeft’s Ocular, built on the core foundation of Code Property Graph can enable the process of interpreting information from such a semantic template in order to query for coordinates that might exist in the application’s source code that would cause a vulnerability to manifest.
In the follow up post I will illustrate the value of integrating Sonatype’s OSS index with ShiftLeft Ocular in order to assess if a particular application is vulnerable to deserialization based “gadget” exploit.
image: RawPixel

