


.png?width=610&name=J1_ModernCybersecurityBook_Promo%201200x628%20v2@2x%20(1).png)

Hasan Yasar, a technical director, security engineer, and teacher with more than 25 years of experience in software development discusses how to identify the things that are important and actually contribute to meaningful outcomes in DevOps.
Metrics, Logs, and Reports
First, let’s start with metrics, logs, and reports.
- Logs describe things that have occurred during execution.
- Metrics are quantitative and are normally time-centric.
- Reports describe the results of activities and include a variety of elements, such as observations and assessments.
The key difference between logs and metrics is that they are event-based and time-based, respectively. The DevOps pipeline generates a considerable amount of data in the form of logs and reports during its execution:
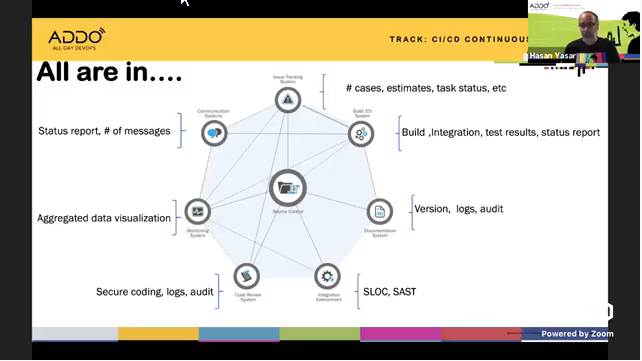
But how can metrics be gleaned from all of this data?
DevOps Metrics
DevOps metrics must help to improve your processes and performance. Sadly, the 2020 State of Software Delivery Management Report found that most software teams can’t quantify how their investments made delivering software easier or more effective. The biggest question is this: How much time or money can be saved by a potential investment? And that goes largely unanswered today.
The focus on measurement is ages old. Using numbers to describe a situation gives you meaningful control to manage it, and that continues today in DevOps.
The right approach is to use goal-question-metric-indicator method to provide structure around a metrics initiative.
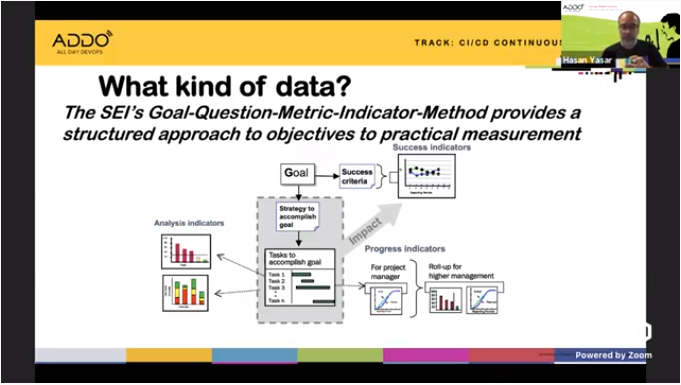
Good Metrics
With the goal of finding metrics that help you improve, it’s possible to differentiate between good and bad metrics. Good metrics have the following characteristics:
- Relevant
- Observable
- Actionable
- Traceable
- Reliable
- Automatable
- Auditable
- Collectible
Other treatments of good versus bad metrics include the DevOps metrics pyramid, which moves from business performance measures such as earnings and cash flow down to operational efficiency measures.
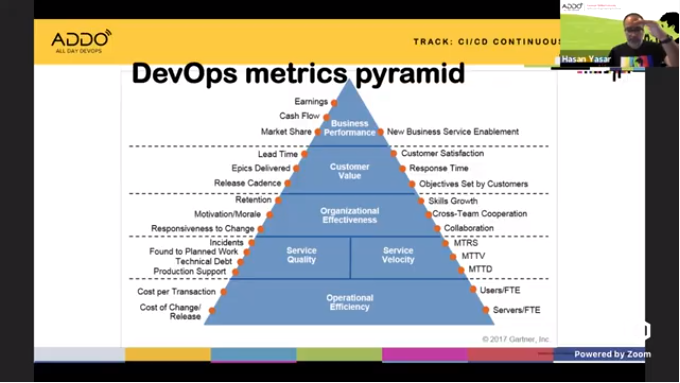
You can find good metrics by following a few guidelines:
- Don’t rely on a single measure
- Use trends and outliers, rather than averages, to find imbalances
- Differentiate outcome measures that affect the customer from process measures
DevOps pipelines have a lot of activities that offer opportunities to measure, such as code submissions and defects found, but these need to be evaluated using the above guidelines. They can be categorized according to qualities such as productivity, reliability, quality, security, and operations.
Monitoring
The goal of monitoring is to provide end-to-end visibility within a process by collecting, interpreting, and aggregating information that’s gathered from a system. Ideally, all stakeholders will be able to view the activities through a dashboard, and the monitoring platform makes it easy to consume and understand them.
Similar to DevOps metrics, monitoring can fall into a number of categories. There are differing rationales as to why you might classify monitoring under any one of these six categories:

Monitoring can be added to a system in a number of ways, including instrumentation via application code and telemetry through automated collection. It must be connected with storage, and you should set up alerts so people can act upon it. Combining metrics and monitoring data together in a single store like a data lake enables capabilities like artificial intelligence, which can now be used to drive performance through analysis and prediction.
The dashboard is a critical tool that helps stakeholders work with the metrics and monitor data. A good dashboard design will clarify the source of the data, make it easy to identify what is actionable, and support follow-up activities such as monitoring adjustments. It’s possible to collect a considerable amount of data, and a great dashboard makes it available to the user without overwhelming them.
Takeaways
The key takeaway from this talk is to identify the DevOps metrics that are critical to success and establish monitoring around them. Focus on high-quality metrics and avoid vanity metrics or ones that cause personal conflict. Additionally, be sure to continually learn and evolve the processes and the associated metrics to achieve ongoing success.
This session was summarized by Daniel Longest. With over a decade in the software field, Daniel has worked in basically every possible role, from tester to project manager to development manager to enterprise architect. He has deep technical experience in .NET and database application development. And after several experiences with agile transformations and years spent coaching and mentoring developers, he's passionate about how organizational design, engineering fundamentals, and continuous improvement can be united in modern software development.

