


.png?width=610&name=J1_ModernCybersecurityBook_Promo%201200x628%20v2@2x%20(1).png)

To kick this session off, Jennifer Petoff, Google's Director of SRE Education, first asks “why antipatterns?” In short, identifying antipatterns helps identify issues and continuously improve our systems.
So, what are the antipatterns? Here’s a list of truths that should help you understand:
- Users shouldn’t notice an outage before you do.
- Engineer solution to eliminate classes of errors rather than being satisfied with point fixes.
- Don’t feed the machine with human toil.
- Failure is an opportunity to improve, not brandish pitchforks.
The Coffee Shop
Let’s talk about the coffee calamity. Petoff was once at a cafe, and she waited for service for 10 minutes. No one had come. Finally, a harried member of the wait staff came to help. The server was the only one working the floor, they explained, and they couldn’t keep up. Petoff ordered a coffee and asked for the menu. But then 10 minutes later, still no coffee arrived.
After a while, the coffee finally showed up. But alas, the menu never did. On the way out, Petoff mentioned to the manager that things were not okay. However, the manager waved it off, indicating that things were quite fine in their mind. But from the customer’s standpoint, this cafe was not meeting service-level objectives (SLOs).

Later Petoff found a cafe with N+2 wait staff, provided faster service, making for a better experience.
Obviously, this cafe reduced toil, perhaps having read the Google SRE Book!
Lessons From the Coffee Story
What can we take away from this?
If you don’t meet expectations, your customers will leave you. And overloading your people will result in burnout. So consider what your customers expect and plan accordingly for capacity.
The Door That Didn’t Lock
In another tale, Petoff visited a hotel that had a nonfunctioning lock. After she called the front desk, someone came up and confirmed that the lock wasn’t working. They promised to call back soon.
After fifteen minutes, no one came. It seemed that no action was taking place. As Petoff had to leave for work, frustrations ran high.
Petoff suggested getting another room—a seemingly simple mitigation—but the person at the desk couldn’t authorize it. They didn’t have the power to solve the problem.
Eventually, though, she was moved to a new room and the problem was resolved. And in the eyes of the manager at the hotel, case closed.
Tying the Hotel Story Back to SRE
Let’s look at this from an incident management standpoint. When you’re in a hotel room that doesn't lock, that’s an incident.
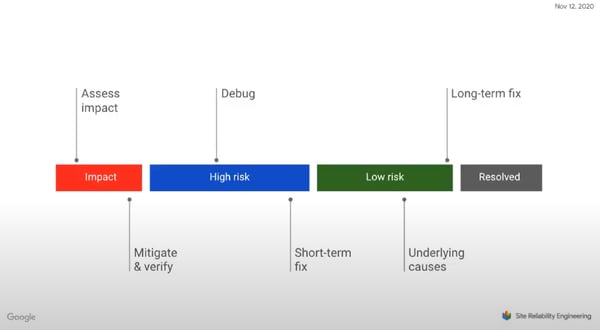
Once you assess the impact, you’ll want to mitigate the issue.
But the story doesn’t end. After mitigation, you still need to figure out what caused the incident, implement a long-term fix, or determine how to prevent the problem in the future.
After further investigation, Petoff learned that the problem resulted from a cleaning staff keycard. But how will this incident be resolved in the future?
The manager had tracked the issue down to human error. But human errors are really systems problems.
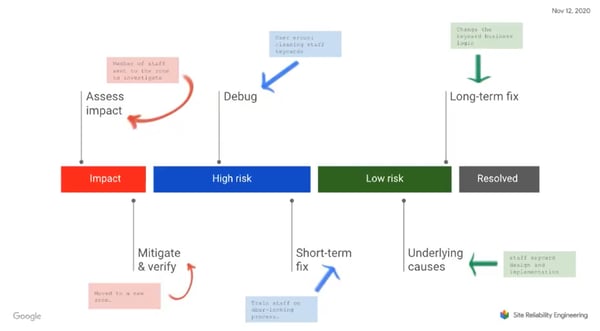
Putting on our SRE hats, we’ll find we want to look at long term fixes and prevention. Perhaps doors can reset automatically after a certain point. Or the keycard logic can be changed to prevent this issue.
Lessons From the Hotel Story
So what can we take away from this story?
- Trust is hard to gain and easy to learn, so you must have empathy for your customer.
- Teams need to be empowered to solve problems
- It’s never human error. These are system problems.
- Don’t settle for point fixes. Instead, put long-term fixes into place.
As we mentioned earlier, SREs realize that to err is human, and you have to engineer out the potential for humans to make these errors.
Why Is SRE Focused on Blameless?
If you know you can be blamed when something goes wrong, you’re incentivized to hide things when they do eventually go wrong. And go wrong they will.
Failure happens, there’s no way around it. So embrace failure and acknowledge things have gone off the rails. This can improve handling of the incident. Plus, you open up the opportunity to address the point of failure, which results in more robust systems.
What can we take away from this?
Put away the pitchforks; they don’t help. Failure is an opportunity to improve. You’ve already paid a price for the outage, so learn as much as you can. And remember that human error is never the root cause.
This session was summarized by Sylvia Fronczak. Sylvia is a software developer that has worked in various industries with various software methodologies. She’s currently focused on design practices that the whole team can own, understand, and evolve over time.

