


.png?width=610&name=J1_ModernCybersecurityBook_Promo%201200x628%20v2@2x%20(1).png)

For many users, software often isn’t really appreciated until you don’t have it. In this day, it’s constant availability has become a given, but, of course, 100% availability isn’t really a reality. That is why when high-profile systems, like Netflix or AWS have outages, it makes national news. Most of us don’t work on systems that garner national user bases, but our users are just as important. So, we work hard to reduce system outages.
Where do problems arise that cause system outages? What can be done to improve processes to reduce system outages?
Researchers see that system outages often stem from problems during operations processes, such as upgrading software. Dr. Ingo Weber (@ingomweber) is one of those researchers. He is a principal research scientist and team leader at Data 61, a part of CSIRO, Australia’s government-funded research body. He and his fellow researchers developed an approach and tool framework, Process-Oriented Dependability (POD), to address this challenge in DevOps practices. POD enables fast error detection, root cause analysis, and recovery.
Ingo shared his insights on POD during his talk, Increasing the Dependability of DevOps Processes, describing the approach, tool, and some key findings.
Ingo set the stage by quoting a Gartner study showing that, “80% of outages impacting mission-critical services will be caused by people and process issues.” Thus, showing that by addressing process issues, you can significantly reduce system outages.
He also notes that with significantly shorter release cycles, moving from months between releases and scheduled downtime to continuous delivery and releases delivered in hours or days, magnifies the potential issues. As an example, he notes that Etsy has a average of 25 full deployments/day and 10 commits per deployment. Because of this, baseline-based anomaly detection no longer works because of cloud uncertainty and continuous changes, such as multiple sporadic operations at all times, scaling in/out, snapshots, migrations, reconfigurations, rolling upgrades, and cron-jobs.
The POD approach at a high-level is:
- Increase dependability during Operation time through:
- More accurate performance monitoring
- Faster error detection
- Fast or autonomous healing (quick fix)
- Root cause diagnosis to figure out what the actual problem is
- Guided or autonomous recovery
- Incorporating change-related knowledge into system management
- Build knowledge about sporadic operations in Process-Oriented Dependability model
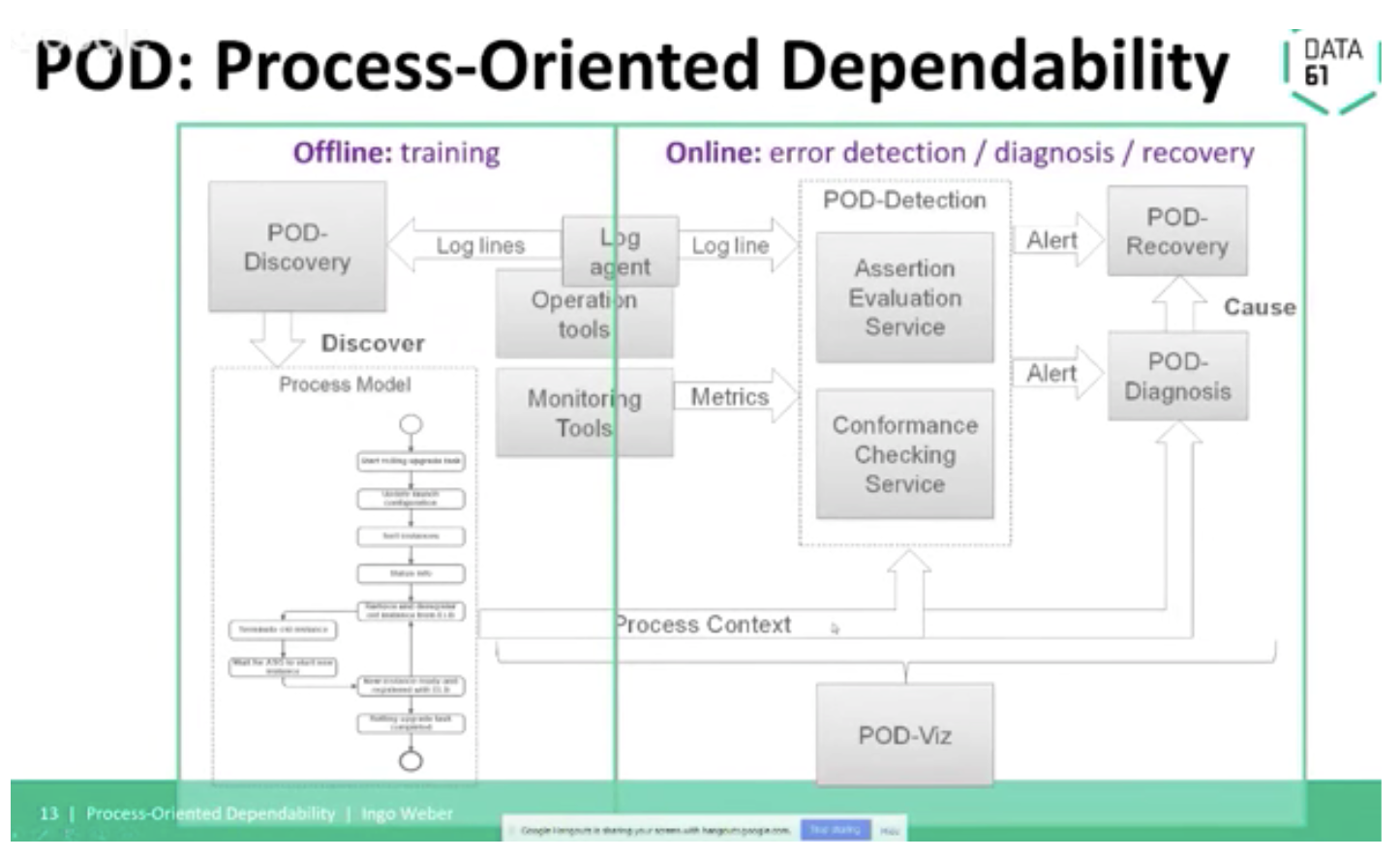
Digging a little deeper into POD, Ingo talks about two approaches they use: Conformance Checking and Assertion Evaluation.
There are three levels of Conformance Checking:
- Basic
- Detecting numerical invariants
- Detecting timing anomalies
When errors/anomalies are detected, an alert is raised, and all results are visualized through POD-Viz, the dashboard.
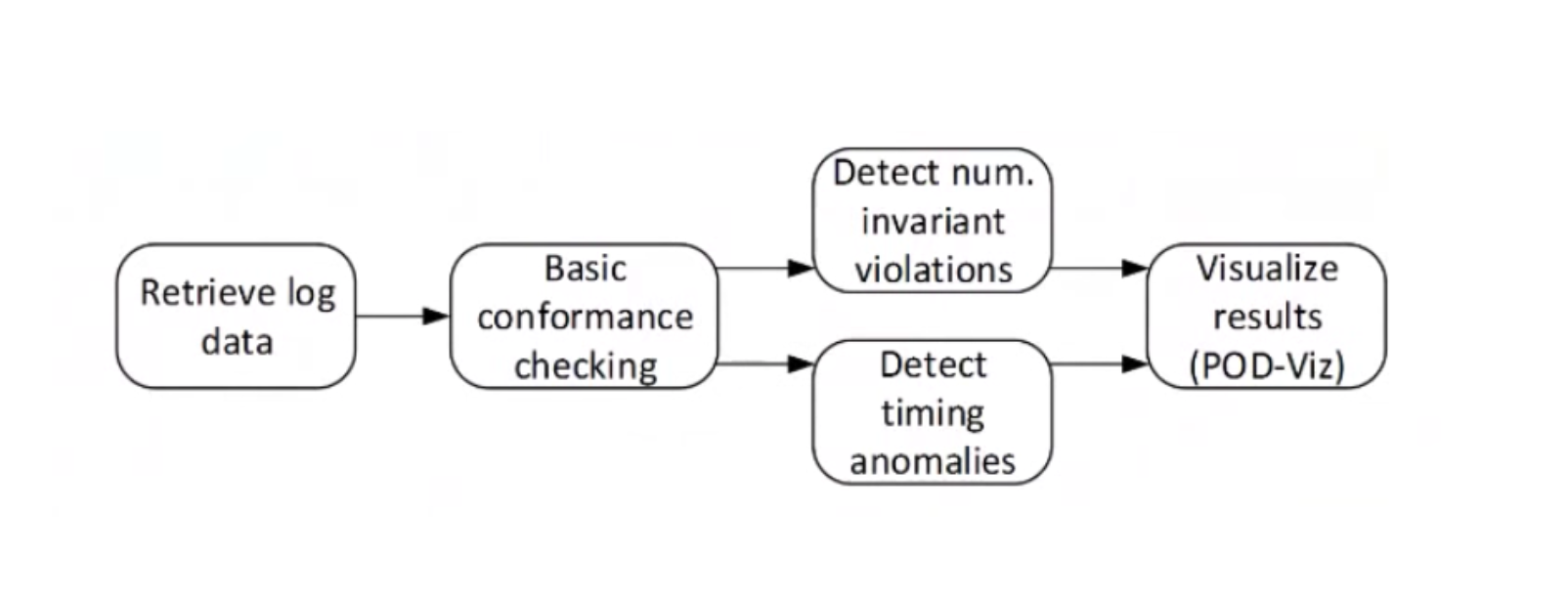
Conformance Checking can detect the following types of errors:
- Unknown/error log line: a log line that corresponds to a known error, or is simply unknown
- Unfit: a log line corresponds to a known activity, but said activity should not happen in the current execution state of the process instance
All other log lines are deemed fit. The goal is 100% fit, otherwise raise an alert and learn from false alerts to improve classification and/or the model.
Assertion Evaluation creates and checks against assertions. Assertions check if the actual state, at a given point, is the expected state. They are coded against cloud APIs so they can find out the true state of resources directly. You also identify the main factors affecting a resource and identify the log events that have the most important influence on changing the state of a system resource. Look at the metrics and chose whose are most relevant, then derive a formula that can be used to estimate the value of a variable associated with a system’s resource so that you can test it against a range of acceptable values. Then, you drive an assertion based on this.
Does Process-Oriented Dependability sound like something you might want to implement or consider further? Ingo’s full talk is especially geared toward practitioners, diving into more detail and examples. It is available to view in its entirety for free here. Additionally, he suggested two papers: Process-Oriented Dependability and Software Performance Engineering in the DevOps World.
Craving more on DevOps practices, binge watch any of the 157 practitioner-led sessions, free of charge, at All Day DevOps.

