


.png?width=610&name=J1_ModernCybersecurityBook_Promo%201200x628%20v2@2x%20(1).png)

Today we’re going to talk about reliability and resiliency. But first, we’re going to go back in time and listen to speaker Casey Rosenthal, cofounder and CEO at Verica, speak about ships and shoes.
Ships and ResilienceA leader put together a research project regarding the ships. He looked at how successful the ships’ routes were, how risky the ships were to sail on, and the mortality rate of the ships.
To give you an idea of what life was like on these ships, it was fairly dangerous but profitable. There was a fortune to be made and an incentive to take risks. Though the captains had the same weather reports, the ship captains made different decisions based on their risk tolerance.
The captains that took more risks typically were more profitable. What was interesting is that the captains that took more risks also had lower mortality. That’s because they built up their skills to deal with surprises at sea. The ones that didn’t take risks didn’t know how to deal with surprises
This is where Rosenthal’s interest in resiliency emerged.

Shoes and Resilience
Next, Rosenthal talked about the shoe business. Back in the 1850s, the streets were filthy, and people constantly needed to get new shoes. So the shoe industry grew rapidly. The shoe stores had racers that would make marks with chalk to indicate how many shoes were needed at different locations. This worked when things were slow, but when things were hectic, people would get ahead of themselves and mark extra chalk marks, in anticipation for additional shoe needs. Then, the wrong number of shoes would show up.
Again, small decisions were causing larger outside impacts. People were making what they thought were the right decisions, but from a higher level, it caused issues.
Tying it Back to Software
The key is that we’re trying to balance between economics, workload, and safety.
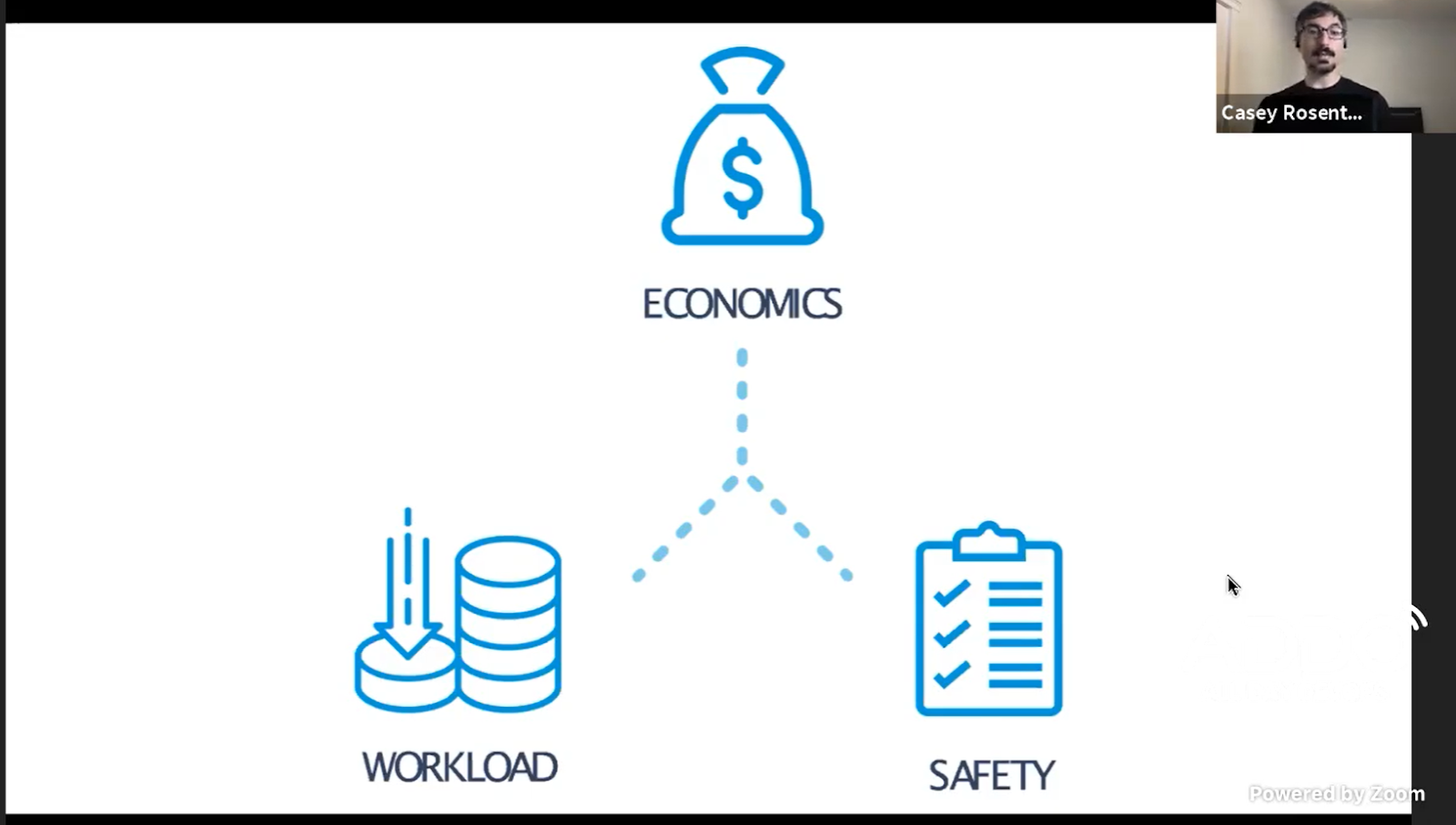
For example, you probably don’t want engineers to spin up 1,000 instances of a service. There might not be a rule against this, but you expect engineers to understand that these instances cost money. This doesn’t need to be explained because they understand the implications.
Similarly, engineers negotiate workload because they understand that there’s a margin that they can’t stretch. With safety, it’s similar, but there’s one difference. Security folks don’t always know how far to stretch. We still have security incidents. In fact, we can’t stop security incidents before they happen because we don’t know about them until they happen.
Enter Chaos Engineering
So what can we do? We can build in chaos engineering. By adding chaos into the system, we can become more resilient to risk. Chaos engineering can help us move the needle on security and reliability.

The quote above about software engineering shared by Rosenthal is actually about bureaucracy. But it applies to software engineering. After all, software engineering is a bureaucratic profession. Why? Because no one decides how the work needs to be done, or what work needs to be done, from the people that actually do the work.
We have team leads, managers, architects. All pull the decisions away from the software engineers that have been hired to solve the problems.
Many companies view this as the ideal model. This goes back to scientific management as it works for manufacturing widgets. But we’re not manufacturing widgets. We’re doing knowledge work. Here, you want the engineers to be empowered to solve the problems.
What Are the Myths of Reliability?
Let’s look at some myths.
Myth 1: Removing the people who cause accidents will solve the problem.
They tried to do this in a hospital by removing the doctors that had the most accidents. However, what they found is that those doctors knew how to deal with difficult situations. Malpractice suits went up because inexperienced people didn’t know how to deal with those situations.
Myth 2: Document best practices and runbooks.
Why doesn’t this work? Now, we’re not saying don’t document things. However, the skills necessary for a resilient system requires improvisation. You can’t always communicate an adaptive capacity through the written word. Usually, it doesn’t work.
Myth 3: Defend against prior root causes.
The problem with this particular myth is that, in a complex system, there are no root causes. You can’t blame someone for writing a bad algorithm. The developer was optimizing for the directions given. So it could be the manager’s fault, or the VP’s fault, or maybe even the CTO’s fault for not setting context and alignment.
Additional risks can be found around enforcing procedures and avoiding risks. But guardrails don’t help.
Takeaways
Again, we can’t take all the complexity out of complex systems. We build resilience by being confronted with problems. Add chaos to your systems to build your system resiliency and your engineer’s resiliency knowledge, and you’ll be poised to succeed.
This post was written by Sylvia Fronczak. Sylvia is a software developer that has worked in various industries with various software methodologies. She’s currently focused on design practices that the whole team can own, understand, and evolve over time.
Photo by Fred Kearney

